nftables 入门:从配置文件到端口转发
这学期前,学校防火墙迎来一波升级,路由器上本来用于绕过多设备封锁的方式尽数失效,考虑到它还跑着非常古老且风评不佳的修改版 OpenWrt,也是时候进行一点系统升级了。新系统最先困扰我的问题就是防火墙变动,OpenWrt 22.03 起,防火墙由 fw3 切换到了 fw4 ,底层也从 iptables 变成了 nftables 。相较于 iptables,nftables 配置更灵活,语法更友好,并且可以直接接管 Xtables ——或者说此前整个 iptables 大家族——的功能,从 ipset 到 mangle 无所不能,但对于习惯 iptables 的用户来说,底层突然切换无疑会带来一定学习成本。
好在, nftables 的强大并不意味着它难以上手。正相反,花两天时间与它相处后,我发现借助详尽的 官方 wiki ,我能迅速熟悉这个新工具,甚至开始依赖起它带来的一些新特性。虽然 iptables-nft 可以非常方便地将 iptables 语句翻译为 nftables 配置,但它毕竟只是一个转换,更适合用于兼容古董软件,而且一些高级特性也无法被它正确识别,掌握如何自己配置 nftables 依旧重要。因此我将我的经验写在这里,希望能帮到更多初次接触 nftables 的读者。
本文默认读者拥有初步的 Linux、SSH 及计算机网络知识,否则可能会因为专业术语过多而导致理解困难,还请谅解。
我的设备为红米 AX6,系统为自己从源码构建的 ImmortalWrt 23.05 SNAPSHOT,部分操作在不同设备上可能不同。
事实上,官方 wiki 对于上手来说也非常不错,如果英语阅读能力过关,可以直接参考 Quick reference-nftables in 10 minutes 。
原理:从 Netfilter 说起
Netfilter 是 Linux 内核中的一个用于管理数据包的框架。一切数据包都从 Netfilter 经过,经历如下图所示的周期。在 prerouting、input、output、forward 和 postrouting 阶段,Netfilter 允许 iptables 和 nftables 这样的应用程序对数据包进行控制,这也正是防火墙的基础。

这张图标题为 Packet flow in Netfilter and General Networking ,这里将它称为「原理图」。原理图也许有点杂乱,我们把它拆开来说。不难看出,从下到上是经典的四层式 TCP/IP 模型,从左到右则是数据包流经设备的全过程。在最底层代表数据包传递的 Xtables 里,这一部分由 ebtables 负责,在此暂且略过。
再敲敲小黑板,这张图相当重要。无论是初识 Netfilter / iptables / nftables 还是后期编写复杂的防火墙规则,这张图都是每个人不可或缺的伙伴。不过啰唆就到此为止,我们直接上主菜吧!
初识配置文件
nftables 的配置工具 nft 提供了方便的防火墙管理,在 OpenWrt 的 SSH 终端中输入 nft list ruleset 就能显示目前的配置文件详情。虽然 nft 本身能够像 iptables 一样用作命令行配置工具,但相比使用命令,撰写分块配置文件更符合我个人的编程习惯,启用、禁用都很自由,跳转、参数设定更自然,不需要每次防火墙重启都执行一遍,而且在优先级方面有更多调整空间。不过更主要的原因是,我使用 nft 的次数微乎其微,大部分时候都是直接撰写配置文件,因此在此略过命令行配置。
总之,如果成功执行了 nft list ruleset ,这时终端里应该会跳出来类似这样一大段:
table inet fw4 {
……
chain inbound_world {
ip saddr 111.222.111.222 tcp dport 22 accept
}
chain input1 {
type filter hook input priority 0; policy drop;
iifname vmap { lo : accept, pppoe-wan : jump inbound_world }
}
……
chain postrouting1 {
type nat hook postrouting priority 100; policy accept;
ip saddr 192.168.0.0/16 oifname pppoe-wan masquerade
}
……
}对于有代码基础的人,这一长串应该比较直观,如果仍旧觉得看起来很复杂,没关系,我们一条一条看。
最外层的 table inet fw4 声明了一个命名为 fw4 的、控制 IPv4 以及 IPv6 ( inet ) 的表 ( table )。借用官方 wiki 的 介绍 ,表是 nftables 最外面的一层,有表才能有链 ( chain )、集 ( set )、映射 ( map ) 等。表的声明由三个部分组成,即 table 关键字、表的 family 以及表名。前后都很好理解,中间的 family 声明处理的协议,只有这些协议的数据包才会流经这个表。本例中, inet 声明这个表需要处理 IPv4 与 IPv6 的数据包,写成 ip 则仅处理 IPv4, ip6 则仅处理 IPv6。类似地, family 还可以是 arp , bridge 或者 netdev ,可以在官网的 family 说明 找到更多信息。
对于我们来说,重头戏是表中间的链 ( chain ) ,它是规则 ( rule ) 的集合。熟悉 iptables 的人知道,它提供了一系列预设好的链,例如 INPUT、OUTPUT,分管数据包路由中不同的阶段。在 nftables 中则不同,链链生而平等,仅有类型 ( type ) 、钩子 ( hook )、优先级 ( priority ) 不同。在表中定义好的链,会在钩子触发的时候,按照链中声明的优先级依次执行。
这么说可能有点绕,我们以那个显眼的 chain input1 作为例子:
chain input1 {
type filter hook input priority 0; policy drop;
iifname vmap { lo : accept, pppoe-wan : jump inbound_world }
}这里 chain input1 中的 input1 是链的名字,它可以随意,只要在表中唯一即可;第二行的 input 则是钩子的类型。上面原理图部分所说的五个阶段,就是我们可以使用的五个钩子: prerouting , forward , input , output 和 postrouting 。如果原理图过于复杂,这里也有一个简化版,直接标注出了 nftables 可用的 hook :
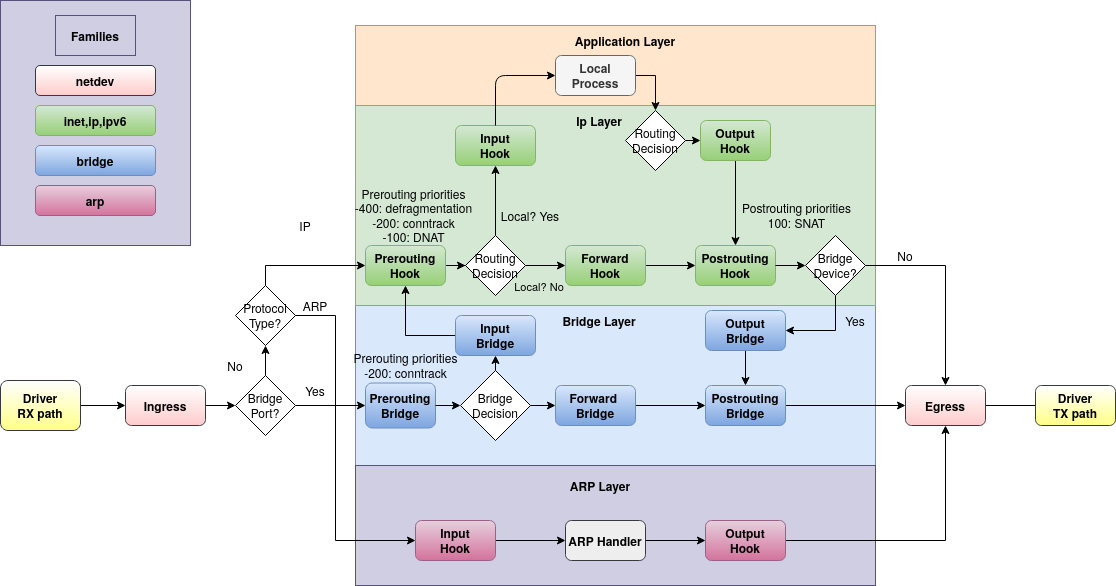
hook 前声明链的类型,这里是 filter ,意味着我们将对包进行 过滤 。除过滤 ( filter ) 外,我们还可以对包进行路由 ( route ) 或 nat 。其中,若我们需要对包进行修改或拦截可以使用 filter , route 可以用来在 output 钩子中对包进行修改,而 nat 则主要用于…NAT。
input 后则是链的优先级,在同一钩子里的链会按优先级顺序,从小到大依次执行。也就是说,如果我添加一个链 input2 ,同样对 input 挂钩子,但是优先级填 -100,这样 input2 会比优先级为 0 的 input1 先执行,不过如果我添加的链是 prerouting1 ,对 prerouting 挂钩子,此时则不管优先级是 -100 还是 100,都会比 input1 先执行。如果此处不太理解,请务必立即回顾原理图。
分号后面的 policy drop ,定义了 所有未经处理的包 在 这个链结束后 的去向,分为两种, accept 与 drop ,前者是不声明 policy 的默认状态,流经这条链的包会继续原理图中后续的流程,后者则是直接丢弃未经处理的数据包。
第三行则是一条具体的处理规则。这条规则比较复杂,它做的事情大概是对来源网卡 ( iifname ) 进行判断:如果来自 lo (即 pppoe-wan ,即 PPPoE 拨号后连接到的广域网,那么跳转 ( jump ) 到名为 inbound_world 的链进一步判断。若不满足这两个匹配规则,这个数据包就会被丢弃,以保护内网安全。
怎样,很简单吧?如果还是有点困扰,我们接着分析上面那一大段 nft list ruleset 的输出中,剩余的两个链:
chain inbound_world {
ip saddr 111.222.111.222 tcp dport 22 accept
}这一条就是上面提及的、来自广域网的包会跳转到的 inbound_world 了。这条链非常简单,它在 ip 层面对来源地址 ( saddr ) 和目标端口 ( dport ) 进行了判断,如果是认识的服务器 ( 111.222.111.222 ) 访问本地 22 端口,则放行 ( accept ) ,否则不处理。根据前面的 input1 链,我们知道其余的包会被直接丢弃。很简单,不是吗?
再捋一遍。我们需要对 IP 进行判断,所以先写下 ip ;接下来判断来源地址 saddr ,即 source address;最后再对 TCP 协议的目标端口 tcp dport 进行判断,即 destination port;判断都通过,我们就能 accept 这个包。同理,如果愿意,还可以对 daddr destination address、 sport source port 之类非常符合直觉的关键词进行组合、叠加,形成一条完整的 nftables 规则。没有复杂的 -a -b -c -X -Y -Z ,需要什么写什么关键词,就是这么简单。
当然,也并非随便什么关键词都能被识别。对于入门来说,推荐参考官方 wiki 中 Matching packet metainformation 以及 Matching packet header 部分,这两个页面以表格形式,列出了绝大部分可以用来判断的关键词及其作用。如果有 conntrack 等高级需求,也可以进一步查阅 官方 wiki 。
chain postrouting1 {
type nat hook postrouting priority 100; policy accept;
ip saddr 192.168.0.0/16 oifname pppoe-wan masquerade
}通过第一行我们知道,这条链作用于 postrouting 阶段,作用是进行 NAT,优先级为 100,允许未经处理的包通过。第二行则对来自 192.168.0.0/16 的包进行处理,如果它出口网卡 oifname 是 pppoe-wan ,那么就对它进行掩蔽 ( masquerade ) 。这是 PPPoE 上网时比较重要的一个操作,修改包的来源 IP,假装这个包来自拨号的设备,避免将内网地址暴露给外部,也避免了上级网关发现拨号 IP 与数据包的 IP 不一致,导致包被丢弃。
最后可能还需要说明,关于分号的使用,nftables 并不严格, 似乎 行末分号的有无并不会影响配置。在 链的配置 中,nftables 官方说:
Important: nft re-uses special characters, such as curly braces and the semicolon. If you are running these commands from a shell such as bash, all the special characters need to be escaped.
这是整个官方 wiki 中唯一提及分号的部分,我不太确定这个模棱两可的 re-uses 具体是需要还是不需要,从实际配置中看来 似乎 与 Kotlin 这类不严格要求分号的语言类似,若一行中存在两条规则,例如 type filter …… ; policy accept; ,则需要在各条结束后加上分号,若没有则不需要。如此看来,大部分时候按照习惯来即可。
实战:端口转发
最后,让我们试着向 nftables 中添加我们自己的配置文件,这里以端口转发为例。端口转发是一类相对常用的防火墙配置,用于将外部的访问转发至本机或内网某一主机。OpenWrt 网页端后台的防火墙配置页面已经提供了方便的配置工具,不过既然决定要学着用 nftables,不如一起来看看如何操作。
这里就引入了第一个问题:我已经知道配置文件的组成,但是配置文件在哪里呢?在以 fw4 为防火墙的 OpenWrt 上, fw4 在每次启动时会自动从 /etc/nftables.d/ 读取 *.nft 文件,将它们写入 fw4 表中,只要我们将配置文件放进去后,使用 service firewall restart 重启防火墙就能生效。
需要注意的是,由于 fw4 会将配置文件写入 table fw4 ,因此我们放入 /etc/nftables.d 的配置文件 不能够 包含表,直接写链即可,否则会报错并导致配置不生效。
现在回到端口转发。假设我们内网有一台设备是 192.168.1.100 ,它的 22 端口上跑了一个 SSH 服务器,我希望连接到路由器的 8022 端口时能直接连接到这台内网设备,我们应该怎么做?
第一步当然是拆解需求。回顾原理图我们知道,对一个包该去哪的判断发生在 prerouting 阶段,而我们要进行的操作是将路由器 IP 及端口转换为内网的 IP 及端口,这不就是 NAT 吗?因此,我们需要一个 nat 类型、在 prerouting 生效的链。
而它的优先级呢?查阅官方文档 Netfilter hooks , prerouting 阶段目标地址转换 ( dstnat ) 的优先级为 -100 ,我们既可以直接写 -100 ,又可以使用 dstnat 这个关键词。以防万一,我们也可以用一个更高优先级的规则,例如 dstnat - 5 ,保证我们这条链发生在其他链之前。
第二步是对包进行判断,这一步相关文档在官方 wiki Expressions: Matching packets 部分,不过其实通过本文前一节就能知道,我们首先需要判断 ip ,如果它的 dport 是 8022 ,说明这个包可以被转发。以防万一,我们还可以进一步对包的来源进行判断,例如我只希望允许来自 ZeroTier 的流量,而我的 ZeroTier 在 10.244.0.0/16 网段,那么再加一个 saddr 进行判断。如果没有判断目标地址听起来有点不靠谱,我们还可以再加一个 daddr ,仅当明确访问位于 10.244.1.1 的路由器时才响应。
第三步就是进行目标地址转换了。同样查阅官方 wiki,NAT 相关的操作在 Performing NAT ,其中提到只有 nat 类型的链才能执行 NAT,以及目标地址转换的关键词是 dnat to ,我们在后面加上目标 IP 和端口,即 192.168.1.100:22 ,就完成了这条链的配置:
chain redirect_to_internal {
type nat hook prerouting priority dstnat - 5; policy accept;
ip saddr 10.0.0.0/8 daddr 10.244.1.1 tcp dport 8022 counter dnat to 192.168.1.100:22
}聪明的读者可以注意到,这里我们中间还多了一个 counter :这是 nftables 用来统计转发数据包量的工具。像这样放在规则中间,判断之后、操作之前,就能够对通过判断的数据包进行计数 ( counter ),便于判断规则是否生效,通过 OpenWrt 的防火墙管理页面或者 nft list ruleset 命令,都能看到规则的统计数据。
大功告成,现在赶紧把文件保存为 /etc/nftables.d/11-redirect.nft ,再 service firewall restart 看看效果吧!
尾
如此,我们就对 nftables 的原理以及配置文件的撰写有了初步的了解。若要进一步了解 nftables 及其配置, 官方 wiki 是个不错的选择,无论是配置过程中遇到问题还是希望进行更复杂的配置,都能在官方 wiki 找到详尽的说明。各大 Linux 发行版在它们的 wiki 中一般也会包含 nftables 相关页面,介绍对应发行版的相关配置,例如 OpenWrt 的 Firewall overview 或者 Debian 的 nftables 。
这篇文章起笔于 2023 年 9 月,到写下这里已经 12 月,我的鸽子之魂熊熊燃烧,好在最终还是没有让这篇博客变成废稿。本来希望做一些更复杂的配置文件示例及解释,不过作为入门来说似乎过于复杂,不如在基础部分多啰唆几句,将其余部分留给读到这里的读者。可惜,直到最后我也没有搞清楚学校防火墙到底从什么地方检测出多设备,决定干脆直接将流量加密后转发出校,借此规避特征检测,当然这就是另一个故事了。总之,配网愉快~